TL;DR We introduce a novel method to fine-tune cross-attention weights in text-to-image diffusion models, effectively mitigating biases across multiple attributes using a compressed single token embedding. Our approach preserves surrounding attributes, surpassing previous methods in both singular and intersectional bias reduction. Drawing inspiration from NLP, our technique capitalizes on the structured composition of text embeddings in text-to-image diffusion models to achieve disentangled editing.

Existing text-to-image model such as Stable Diffusion exhibit significant biases, including intersectional bias that affects people who are part of two or more marginalized groups (left). MIST finetunes the cross-attention maps of the SD model to mitigate biases related to single or intersectional attributes, such as (gender), (gender & race & age) (right).
Abstract
Diffusion-based text-to-image models have rapidly gained popularity for their ability to generate detailed and realistic images from textual descriptions. However, these models often reflect the biases present in their training data, especially impacting marginalized groups. While prior efforts to debias language models have focused on addressing specific biases, such as racial or gender biases, efforts to tackle intersectional bias have been limited. Intersectional bias refers to the unique form of bias experienced by individuals at the intersection of multiple social identities. Addressing intersectional bias is crucial because it amplifies the negative effects of discrimination based on race, gender, and other identities. In this paper, we introduce a method that addresses intersectional bias in diffusion-based text-to-image models by modifying cross-attention maps in a disentangled manner. Our approach utilizes a pre-trained Stable Diffusion model, eliminates the need for an additional set of reference images, and preserves the original quality for unaltered concepts. Comprehensive experiments demonstrate that our method surpasses existing approaches in mitigating both single and intersectional biases across various attributes. We make our source code and debiased models for various attributes available to encourage fairness in generative models and to support further research.
Method
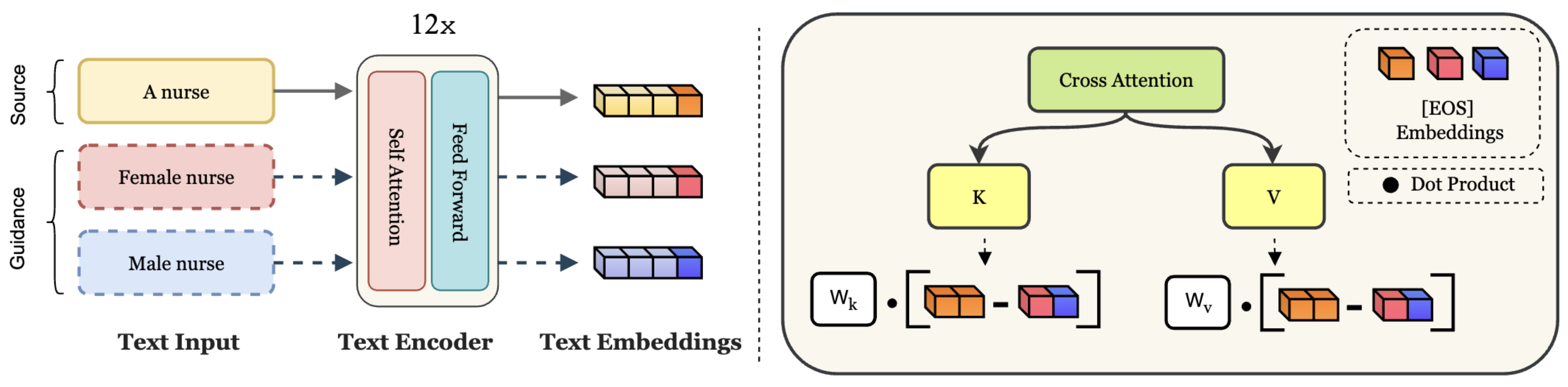
Given a source embedding such as "A nurse" and a guidance embedding such as "A female nurse", MIST debiases the source attribute with respect to the guidance. In particular, we inject the [EOS] token from the guidance into the source embedding (left) to update the cross attention layers in a disentangled manner (right).
Single Attribute Debiasing

Qualitative results on singular debiasing. Samples generated with the same seed using Stable Diffusion are displayed on the left, while samples produced with MIST are shown on the right. Our approach effectively debiases single attributes like gender and race.
Intersectional Attribute Debiasing

Qualitative results on intersectional attribute debiasing. Samples generated with the same seed using Stable Diffusion are displayed on the left, while samples produced with MIST are shown on the right. Our approach effectively debiases intersectional attributes like gender & race, gender & eyeglass, gender & age & eyeglass.
BibTeX
@misc{yesiltepe2024mist,
title={MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models},
author={Hidir Yesiltepe and Kiymet Akdemir and Pinar Yanardag},
year={2024},
eprint={2403.19738},
archivePrefix={arXiv},
primaryClass={cs.CV}
}